| Bert基础(五) | 您所在的位置:网站首页 › 编码器 解码器 子模块 › Bert基础(五) |
Bert基础(五)
|
1、 多头注意力层
下图展示了Transformer模型中的编码器和解码器。我们可以看到,每个解码器中的多头注意力层都有两个输入:一个来自带掩码的多头注意力层,另一个是编码器输出的特征值。 让我们详细了解该层究竟是如何工作的。多头注意力机制的第1步是创建查询矩阵、键矩阵和值矩阵。我们已知可以通过将输入矩阵乘以权重矩阵来创建查询矩阵、键矩阵和值矩阵。但在这一层,我们有两个输入矩阵:一个是R(编码器输出的特征值),另一个是M(前一个子层的注意力矩阵)。应该使用哪一个呢? 答案是:我们使用从上一个子层获得的注意力矩阵M创建查询矩阵Q,使用编码器输出的特征值R创建键矩阵和值矩阵。由于采用多头注意力机制,因此对于头 i i i,需做如下处理。 查询矩阵Q通过将注意力矩阵M乘以权重矩阵 W i Q W_i^Q WiQ来创建。键矩阵和值矩阵通过将编码器输出的特征值R分别与权重矩阵 W i K W_i^K WiK、 W i V W_i^V WiV相乘来创建,如图所示。 为什么要用M计算查询矩阵,而用R 计算键矩阵和值矩阵呢?因为查询矩阵是从M求得的,所以本质上包含了目标句的特征。键矩阵和值矩阵则含有原句的特征,因为它们是用R计算的。为了进一步理解,让我们来逐步计算。 为什么要用M计算查询矩阵,而用R 计算键矩阵和值矩阵呢?因为查询矩阵是从M求得的,所以本质上包含了目标句的特征。键矩阵和值矩阵则含有原句的特征,因为它们是用R计算的。为了进一步理解,让我们来逐步计算。
第1步是计算查询矩阵与键矩阵的点积。查询矩阵和键矩阵如下图所示。需要注意的是,这里使用的数值是随机的,只是为了方便理解.
查询矩阵与键矩阵的点积结果 计算多头注意力矩阵的下一步是将 Q i ⋅ K i T Q_i·K_i^T Qi⋅KiT除以 d k \sqrt{d_k} dk ,然后应用softmax函数,得到分数矩阵 s o f t m a x ( Q i ⋅ K i T d k ) softmax(\frac{Q_i·K_i^T}{\sqrt{d_k}}) softmax(dk Qi⋅KiT)。 接下来,我们将分数矩阵乘以值矩阵
V
i
V_i
Vi,得到
s
o
f
t
m
a
x
(
Q
i
⋅
K
i
T
d
k
)
V
i
softmax(\frac{Q_i·K_i^T}{\sqrt{d_k}})V_i
softmax(dk
Qi⋅KiT)Vi,即注意力矩阵
Z
i
Z_i
Zi,如图所示。 同样,我们可以计算出h个注意力矩阵,将它们串联起来。然后,将结果乘以一个新的权重矩阵 W 0 W_0 W0,得出最终的注意力矩阵,如下所示。 M u l t i − h e a d a t t e n t i o n = C o n c a t e n a t e ( Z 1 , Z 2 , … … , Z h ) W 0 Multi - head attention = Concatenate(Z_1, Z_2,……,Z_h)W_0 Multi−headattention=Concatenate(Z1,Z2,……,Zh)W0 将最终的注意力矩阵送入解码器的下一个子层,即前馈网络层。 2 、前馈网络层解码器的下一个子层是前馈网络层,如图所示 和在编码器部分学到的一样,叠加和归一组件连接子层的输入和输出,如图所示。 一旦解码器学习了目标句的特征,我们就将顶层解码器的输出送入线性层和softmax层,如图
假设解码器的输入词是和Je。基于输入词,解码器需要预测目标句中的下一个词。然后,我们把顶层解码器的输出送入线性层。线性层生成logit向量,其大小等于原句中的词汇量。假设线性层返回如下logit向量: l o g i t = [ 45 , 40 , 49 ] logit = [45, 40, 49] logit=[45,40,49] 最后,将softmax函数应用于logit向量,从而得到概率。 p r o b = [ 0.018 , 0.000 , 0.981 ] prob = [0.018, 0.000, 0.981] prob=[0.018,0.000,0.981] 从概率矩阵中,我们可以看出索引2的概率最高。所以,模型预测出的下一个词位于词汇表中索引2的位置。由于vais这个词位于索引2,因此解码器预测目标句中的下一个词是vais。通过这种方式,解码器依次预测目标句中的下一个词。 现在我们已经了解了解码器的所有组件。下面,让我们把它们放在一起,看看它们是如何作为一个整体工作的。 5、 解码器总览下图显示了两个解码器。为了避免重复,只有解码器1被展开说明。 我们可以将N个解码器层层堆叠起来。从最后的解码器得到的输出(解码后的特征)将是目标句的特征。接下来,我们将目标句的特征送入线性层和softmax层,通过概率得到预测的词。 现在,我们已经详细了解了编码器和解码器的工作原理。让我们把编码器和解码器放在一起,看看Transformer模型是如何整体运作的。 6、 整合编码器和解码器下图完整地展示了带有编码器和解码器的Transformer架构。 我们可以通过最小化损失函数来训练Transformer网络。但是,应该如何选择损失函数呢?我们已经知道,解码器预测的是词汇的概率分布,并选择概率最高的词作为输出。所以,我们需要让预测的概率分布和实际的概率分布之间的差异最小化。要做到这一点,可以将损失函数定义为交叉熵损失函数。我们通过最小化损失函数来训练网络,并使用Adam算法来优化训练过程。 另外需要注意,为了防止过拟合,我们可以将dropout方法应用于每个子层的输出以及嵌入和位置编码的总和。 以上,我们详细学习了Transformer的工作原理。在后面,我们将开始使用BERT。 |
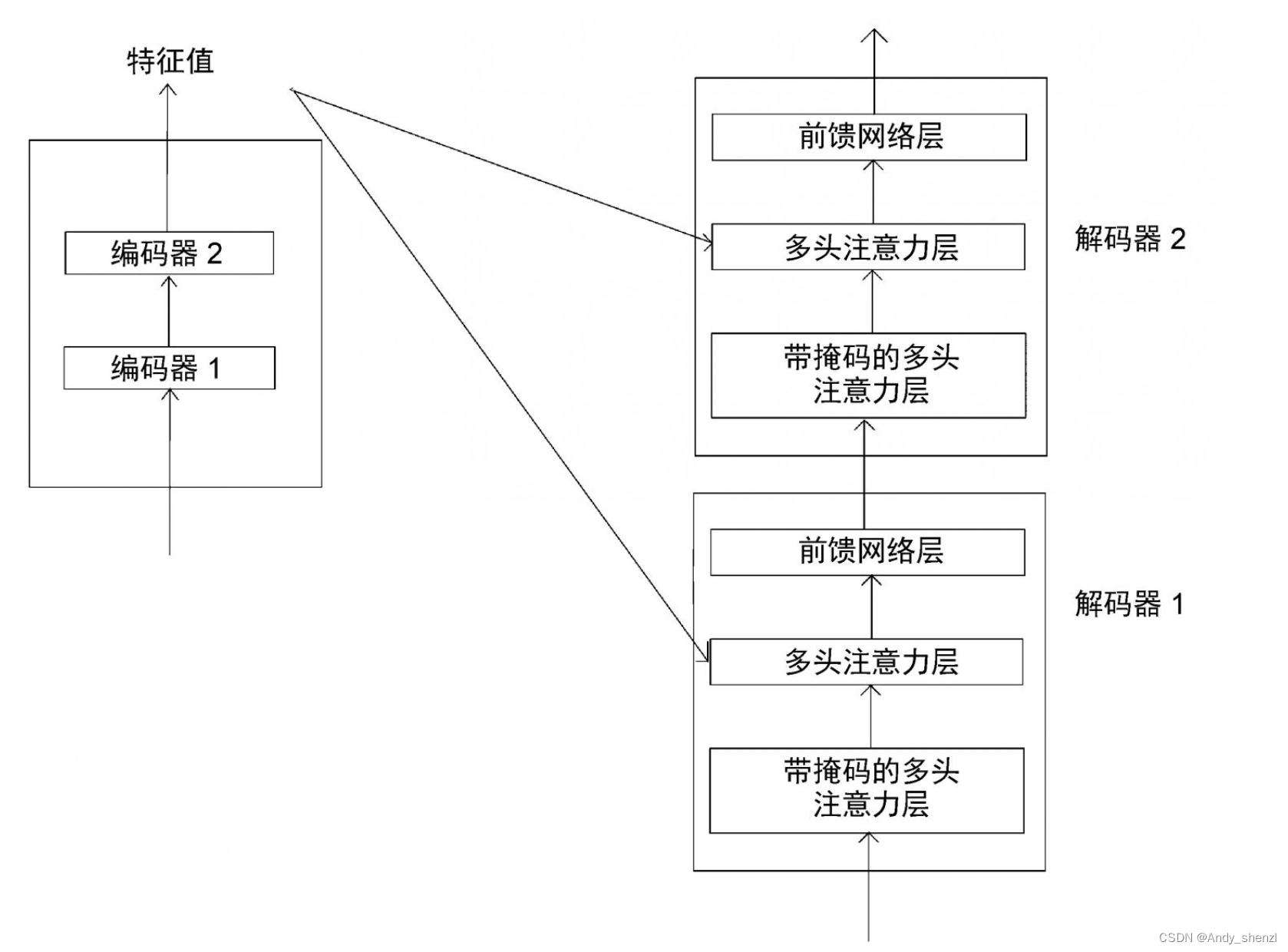 让我们用R来表示编码器输出的特征值,用M来表示由带掩码的多头注意力层输出的注意力矩阵。由于涉及编码器与解码器的交互,因此这一层也被称为编码器−解码器注意力层。
让我们用R来表示编码器输出的特征值,用M来表示由带掩码的多头注意力层输出的注意力矩阵。由于涉及编码器与解码器的交互,因此这一层也被称为编码器−解码器注意力层。
 通过观察图矩阵
Q
i
⋅
K
i
T
Q_i·K_i^T
Qi⋅KiT,我们可以得出以下几点。
通过观察图矩阵
Q
i
⋅
K
i
T
Q_i·K_i^T
Qi⋅KiT,我们可以得出以下几点。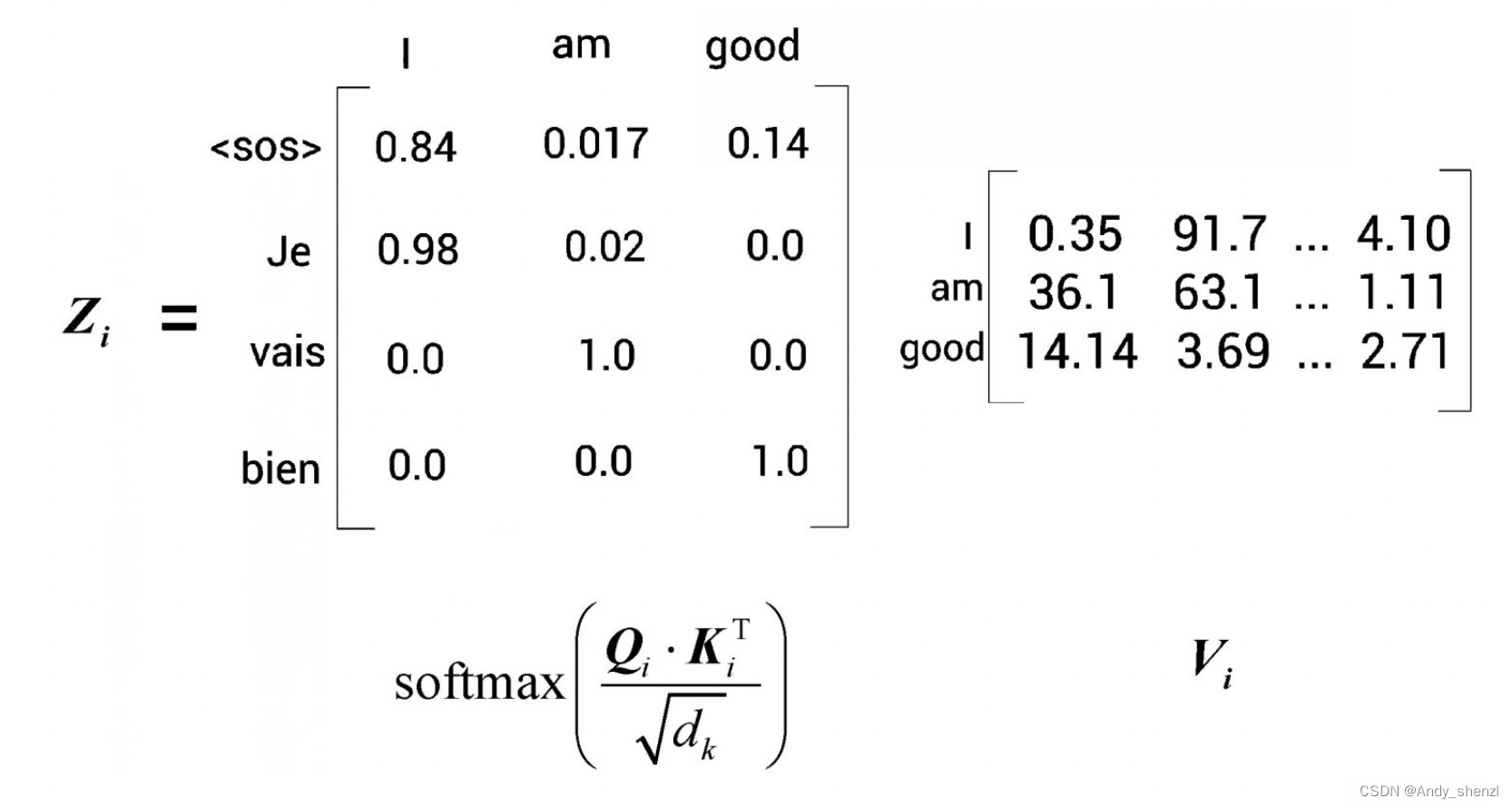 假设计算结果如图
假设计算结果如图 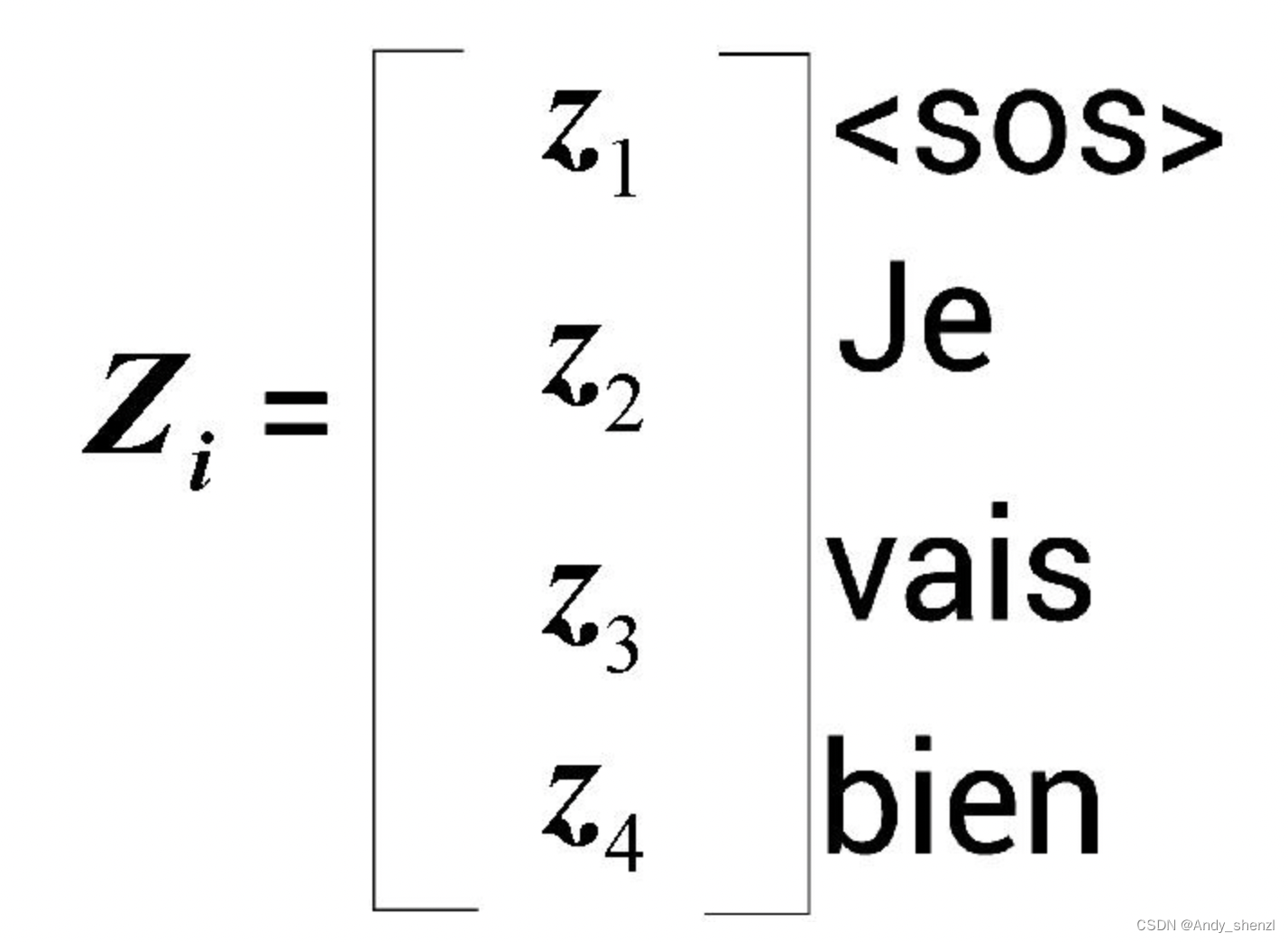 目标句的注意力矩阵
Z
i
Z_i
Zi是通过分数加权的值向量之和计算的。为了进一步理解,让我们看看Je这个词的自注意力值
Z
2
Z_2
Z2是如何计算的,如图
目标句的注意力矩阵
Z
i
Z_i
Zi是通过分数加权的值向量之和计算的。为了进一步理解,让我们看看Je这个词的自注意力值
Z
2
Z_2
Z2是如何计算的,如图  Je的自注意力值
Z
2
Z_2
Z2是通过分数加权的值向量之和求得的。因此,
Z
2
Z_2
Z2的值将包含98%的值向量
v
1
v_1
v1(I)和2%的值向量
v
2
v_2
v2(am)。这个结果可以帮助模型理解目标词Je指代的是原词I。
Je的自注意力值
Z
2
Z_2
Z2是通过分数加权的值向量之和求得的。因此,
Z
2
Z_2
Z2的值将包含98%的值向量
v
1
v_1
v1(I)和2%的值向量
v
2
v_2
v2(am)。这个结果可以帮助模型理解目标词Je指代的是原词I。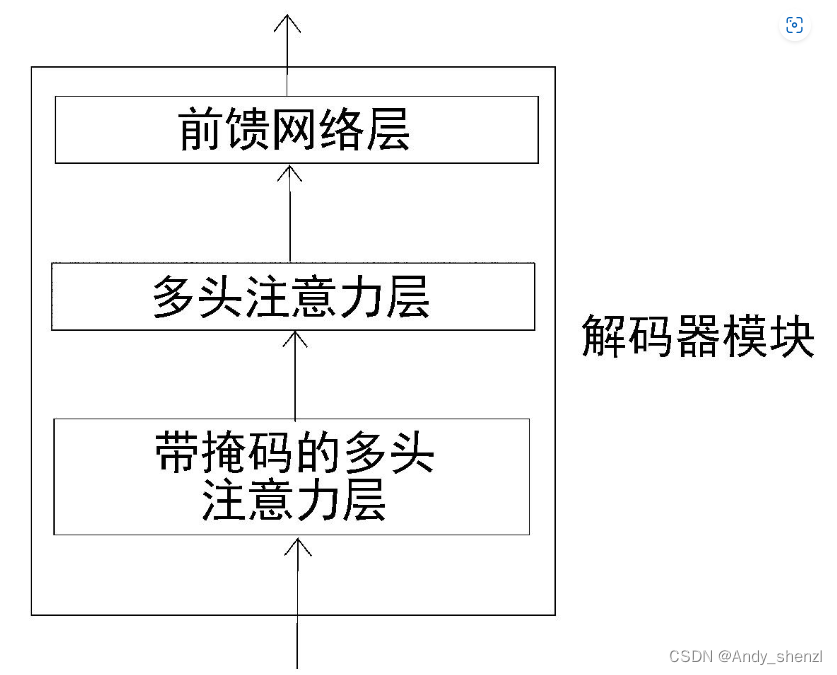 解码器的前馈网络层的工作原理与我们在编码器中学到的完全相同,因此这里不再赘述。下面来看叠加和归一组件。
解码器的前馈网络层的工作原理与我们在编码器中学到的完全相同,因此这里不再赘述。下面来看叠加和归一组件。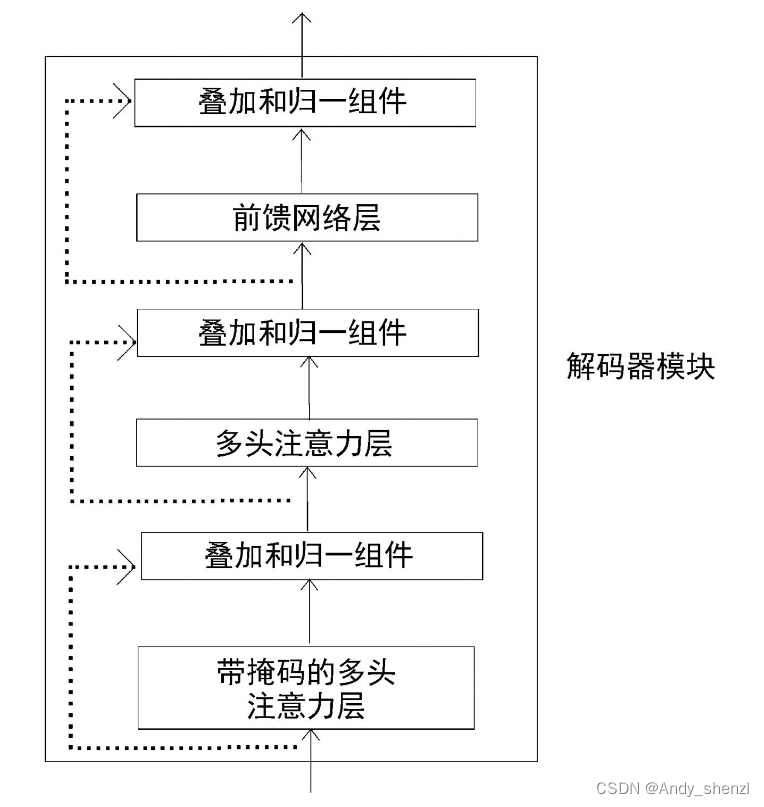
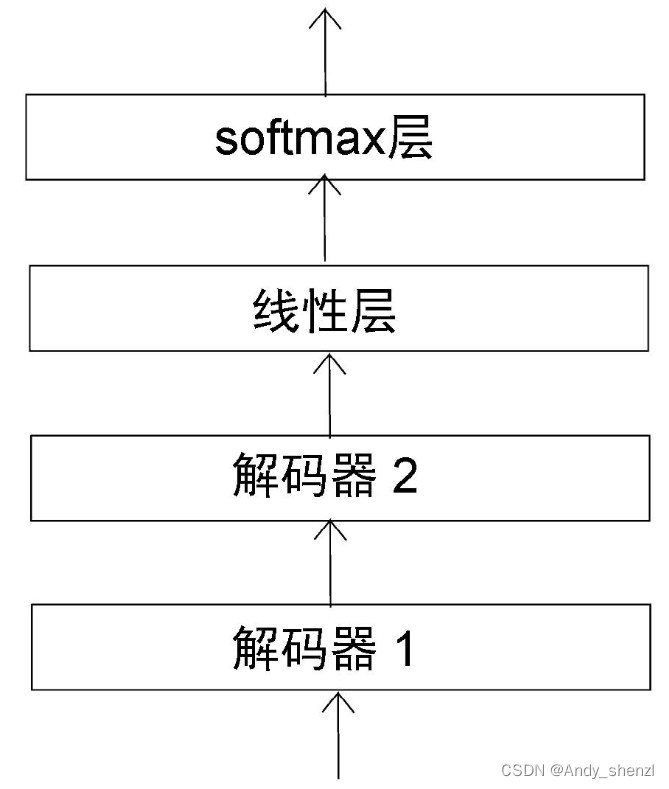 线性层将生成一个logit向量【logit向量是指BERT模型在soft Max激活函数之前输出的概率分布】,其大小等于原句中的词汇量。假设原句只由以下3个词组成:
v
o
c
a
b
u
l
a
r
y
=
b
i
e
n
,
J
e
,
v
a
i
s
vocabulary = {bien, Je , vais}
vocabulary=bien,Je,vais 那么,线性层返回的logit向量的大小将为3。接下来,使用softmax函数将logit向量转换成概率,然后解码器将输出具有高概率值的词的索引值。让我们通过一个示例来理解这一过程。
线性层将生成一个logit向量【logit向量是指BERT模型在soft Max激活函数之前输出的概率分布】,其大小等于原句中的词汇量。假设原句只由以下3个词组成:
v
o
c
a
b
u
l
a
r
y
=
b
i
e
n
,
J
e
,
v
a
i
s
vocabulary = {bien, Je , vais}
vocabulary=bien,Je,vais 那么,线性层返回的logit向量的大小将为3。接下来,使用softmax函数将logit向量转换成概率,然后解码器将输出具有高概率值的词的索引值。让我们通过一个示例来理解这一过程。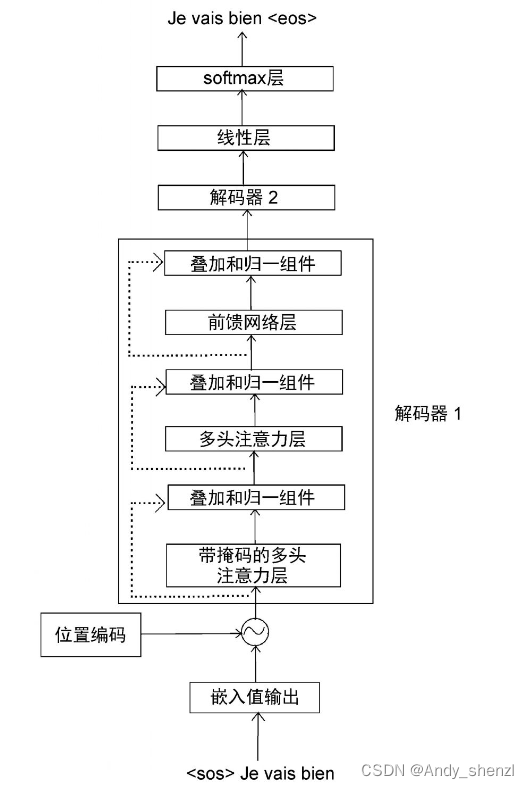 通过图,我们可以得出以下几点。 (1) 首先,我们将解码器的输入转换为嵌入矩阵,然后将位置编码加入其中,并将其作为输入送入底层的解码器(解码器1)。 (2) 解码器收到输入,并将其发送给带掩码的多头注意力层,生成注意力矩阵[插图]。 (3) 然后,将注意力矩阵[插图]和编码器输出的特征值[插图]作为多头注意力层(编码器−解码器注意力层)的输入,并再次输出新的注意力矩阵。 (4) 把从多头注意力层得到的注意力矩阵作为输入,送入前馈网络层。前馈网络层将注意力矩阵作为输入,并将解码后的特征作为输出。 (5) 最后,我们把从解码器1得到的输出作为输入,将其送入解码器2。 (6) 解码器2进行同样的处理,并输出目标句的特征。
通过图,我们可以得出以下几点。 (1) 首先,我们将解码器的输入转换为嵌入矩阵,然后将位置编码加入其中,并将其作为输入送入底层的解码器(解码器1)。 (2) 解码器收到输入,并将其发送给带掩码的多头注意力层,生成注意力矩阵[插图]。 (3) 然后,将注意力矩阵[插图]和编码器输出的特征值[插图]作为多头注意力层(编码器−解码器注意力层)的输入,并再次输出新的注意力矩阵。 (4) 把从多头注意力层得到的注意力矩阵作为输入,送入前馈网络层。前馈网络层将注意力矩阵作为输入,并将解码后的特征作为输出。 (5) 最后,我们把从解码器1得到的输出作为输入,将其送入解码器2。 (6) 解码器2进行同样的处理,并输出目标句的特征。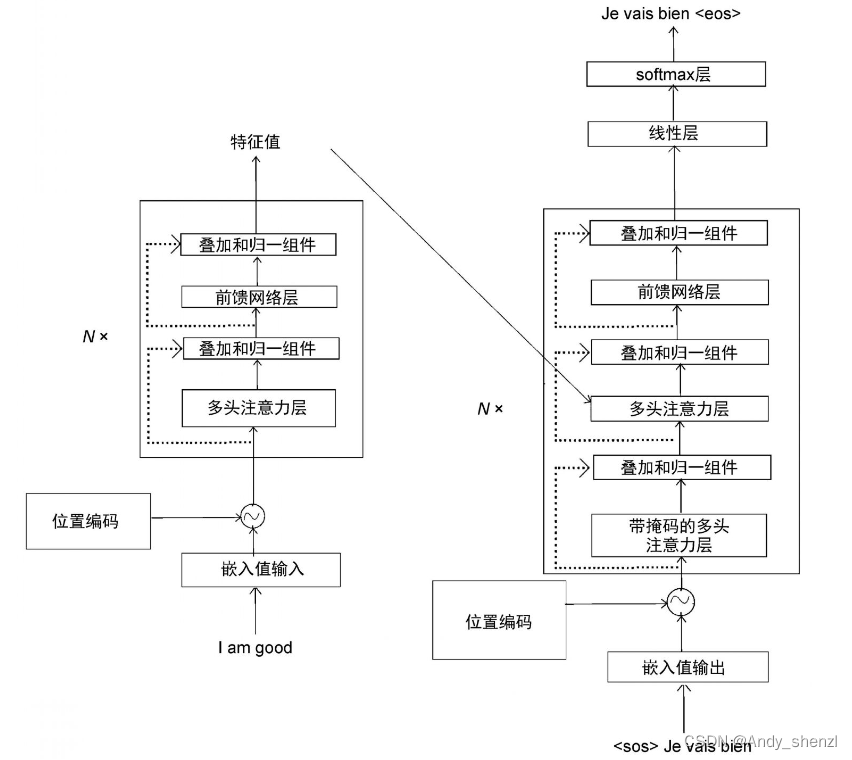 在图1-63中,
N
×
N ×
N×表示可以堆叠N个编码器和解码器。我们可以看到,一旦输入句子(原句),编码器就会学习其特征并将特征发送给解码器,而解码器又会生成输出句(目标句)。
在图1-63中,
N
×
N ×
N×表示可以堆叠N个编码器和解码器。我们可以看到,一旦输入句子(原句),编码器就会学习其特征并将特征发送给解码器,而解码器又会生成输出句(目标句)。【本文地址】